- Solutions
- Products
- Resources
- Company
 Investor Relations
Investor RelationsFinancial Information
- Careers


The Ceva-BX2 baseband processor IP handles both signal-processing and control workloads with up to 16 GMACs per second performance and high-level-language programming. It supports a range of integer and floating-point data types for a wide range of baseband applications like 5G PHY control, and exploits a high degree of parallelism, but with remarkably compact code size. Optimized high-speed interfaces expedite connection to other Ceva cores or to accelerators.
The Ceva-BX2 combines the capabilities of signal processing and control-code execution into a single, compact DSP. Computational speed comes from quad-32×32/octal-16×16 MACs with added support for 16×8 and 8×8 MAC operations, organized into two parallel compute engines within an 11-stage pipeline. Each compute engine can add optional half- and single-precision IEEE floating-point units. These resources are directed by a five-way VLIW instruction set architecture with optimizations for single-instruction-multiple-data (SIMD) operation, including a hardware loop buffer for kernel execution. Efficient execution of control code is aided by dynamic branch prediction and a branch target cache. On signal-processing tasks the Ceva-BX2 can reach up to 16 GMACs per second, and on control workloads it can achieve up to 5.46 CoreMark/MHz. The hardware design is optimized for speed, achieving 2 GHz operation implemented in a TSMC 7nm process node with only common standard cells and memory compilers.
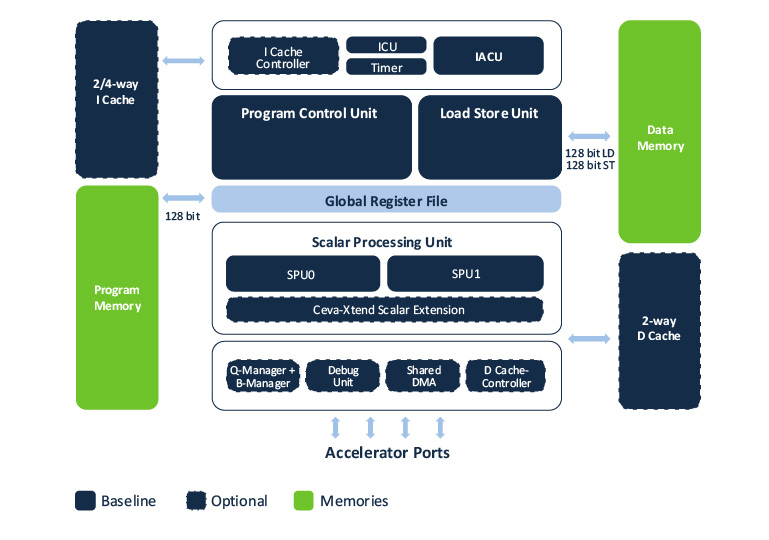
The Ceva-BX2 processor delivers up to 16 GMAC/s for signal processing and up to 5.46 CoreMark/MHz for control tasks, operating at 2 GHz on a TSMC 7 nm process using standard cells and memory compilers
The Ceva-BX2 combines the capabilities of a powerful compact DSP with those of a capable MCU, handling both signal-processing and control workloads in a single core. DSP performance is sufficient for 5G PHY control paths and other communications workloads. High-speed ports with optional automatic queuing and buffer controls make it easy to cluster Ceva-BX2 cores and to attach coprocessors and accelerators. The performance of the Ceva-BX2 can be achieved without assembly coding, using only C/C++ code with an LLVM compiler. The compiler, an RTOS, an Eclipse-based tool chain, extensive libraries for DSP and mathematical operations are all provided.



Get in touch
Reach out to learn how can Ceva help drive your next Smart Edge design
