- Solutions
- Products
- Resources
- Company
 Investor Relations
Investor RelationsFinancial Information
- Careers


The Ceva-XC23 is the most powerful DSP core available today for communications applications. Ceva-XC23 offers scalable architecture and dual thread design with support for AI, addressing growing demand for smarter, more efficient wireless infrastructure
Targeted for 5G and 5G-Advanced workloads, the Ceva-XC23 has two independent execution threads and a dynamic scheduled vector-processor, providing not only unprecedented processing power but unprecedented utilization on real-world 5G multitasking workloads.
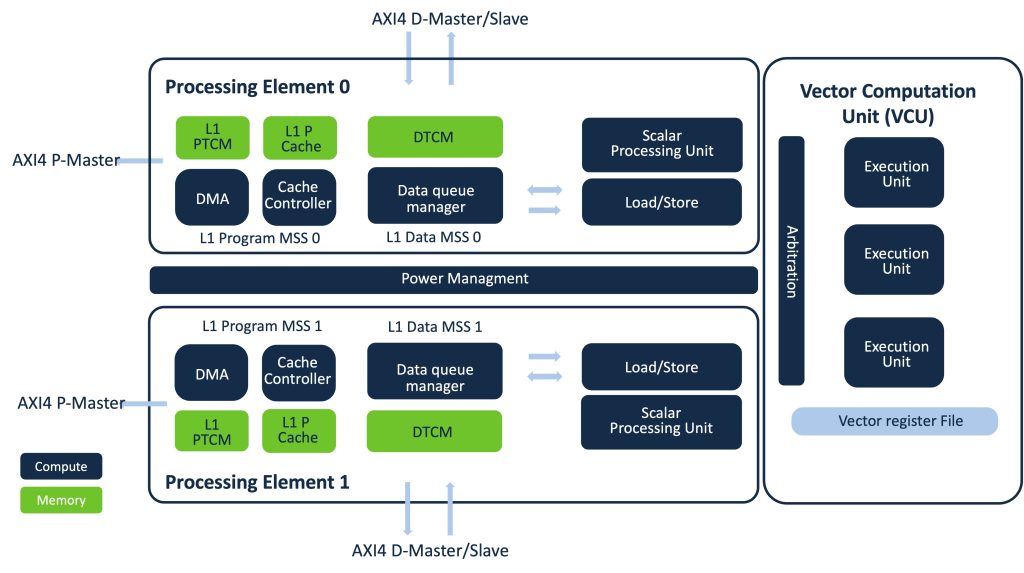
The Ceva-XC23, based on the advanced Ceva-XC20 architecture, features dual execution threads with independent memory subsystems and caches. It includes a shared Vector Computation Unit (VCU) with four engines, dynamically allocated to maximize utilization and reduce contention. The VCU consist of two arithmetic engines, with one non-linear engine and one move-and-scale engine that supports 128 16×16 MACs. The architecture ensures efficient data handling with wide memory connections and dedicated DMA engines.
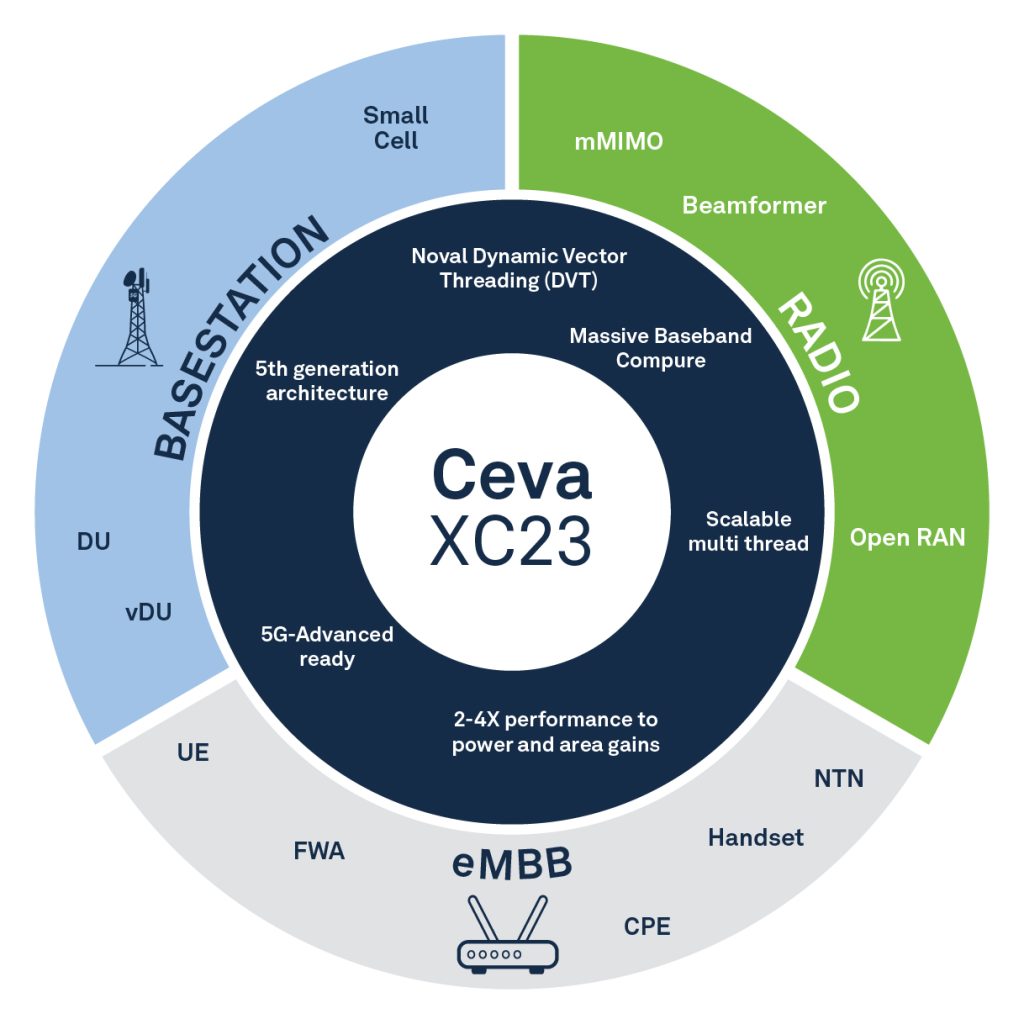
The Ceva-XC23 DSP offers exceptional efficiency in terms of power, performance, and area, making it ideal for 4G, 5G, and 5G-Advanced NR implementations. With AI support and programmability, these DSPs not only enhance modem performance but also enable advanced AI and ML workloads.
It delivers 2.4 times the performance of Ceva’s previous-generation Ceva-XC architecture, while maintaining a compact DSP core design. This allows clusters of Ceva-XC23 cores to achieve extraordinary performance levels while saving precious SoC real estate.
The Ceva-XC23 is software compatible with the Ceva-XC4500 and provides scalable performance across various 5G profiles, includingu RLLC, and eMBB. With a high control code performance of 5.14 CoreMark/MHz, it ensures top-notch performance. The core features a unified programming model across all Ceva-XC20 variants and supports low power modes for system power optimization. The design allows for easy integration into SoCs with standard AMBA4 buses. Additionally, the complete software tool chain includes an optimizing LLVM C compiler for high-level programming, and best-in-class debug capabilities for effective system development.
Tap the image below to watch:

Get in touch
Reach out to learn how can Ceva help drive your next Smart Edge design



