- Solutions
- Products
- Resources
- Company
 Investor Relations
Investor RelationsFinancial Information
- Careers


Edge AI Sensing eBook or Webinar On-Demand: What it Really Takes to Build a Future-Proof AI Architecture
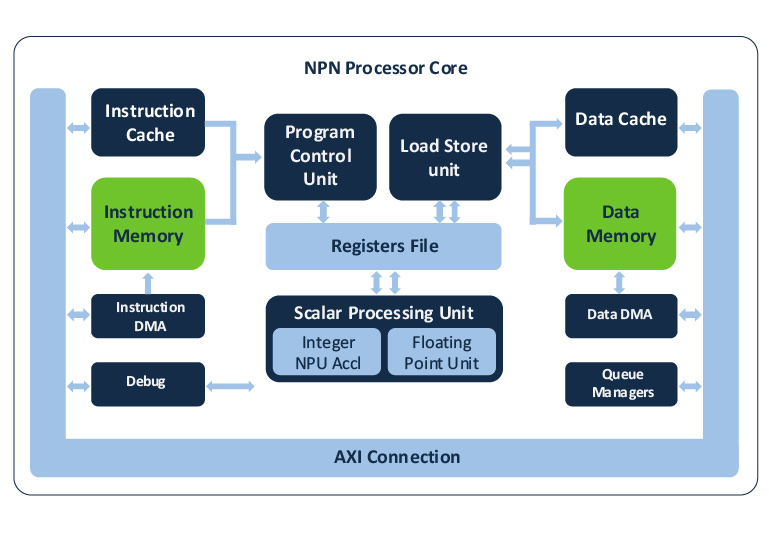
Ceva-NeuPro-Nano is a fully stand-alone neural processing unit (NPU), not an AI accelerator, and does not require a host CPU or DSP. The IP core includes all processing elements of a self-contained NPU, including code execution and memory management.
Key architectural capabilities:
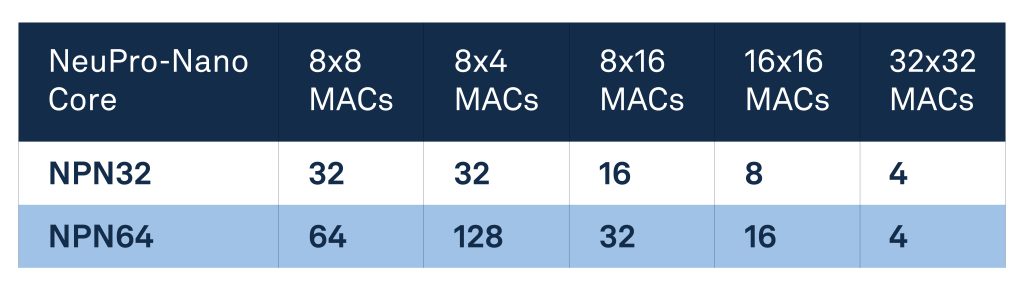
Two cores are available:
Additional advantages:
The Ceva-NeuPro-Nano NPU family is specially designed to bring the power of AI to the Internet of Things (IoT), through efficient deployment of Embedded ML models on low-power, resource-constrained devices. Ceva-NeuPro-Nano NPUs’ optimized, self-sufficient architecture enables them to deliver superior power efficiency, with a smaller silicon footprint, and optimal performance for Embedded ML workloads, compared to the existing processor solutions, which utilize a combination of CPU or DSP with a separate AI accelerator.
The Ceva-NeuPro Studio, which leverages open source AI framework and provides an easy-to-use software development environment, extensive pre-optimized models in the Ceva Model Zoo, and a wide range of runtime libraries, speeds product development for chip designers, OEM’s and software developers.
The EDGE AI FOUNDATION (formerly tinyML Foundation) is a global non-profit community of innovation, collaboration, advocacy and education for efficient, affordable and scalable Edge AI technologies.
![]()






Get in touch
Reach out to learn how can Ceva help drive your next Smart Edge design
