- Solutions
- Products
- Resources
- Company
 Investor Relations
Investor RelationsFinancial Information
- Careers



The Ceva-NeuPro-M Neural Processing Unit (NPU) IP family delivers exceptional energy efficiency tailored for edge computing while offering scalable performance to handle AI models with over a billion parameters. Its innovative architecture, which has won multiple awards, introduces significant advancements in power efficiency and area optimization, enabling it to support massive machine-learning networks, advanced language and vision models, and multi-modal generative AI. With a processing range of 4 to 200 TOPs per core and leading area efficiency, the Ceva-NeuPro-M optimizes key AI models seamlessly. A robust tool suite complements the NPU by streamlining hardware implementation, model optimization, and runtime module composition.
The Ceva-NeuPro-M NPU IP family is a highly scalable, complete hardware and software IP solution for embedding high performance AI processing in SoCs across a wide range of edge AI applications.
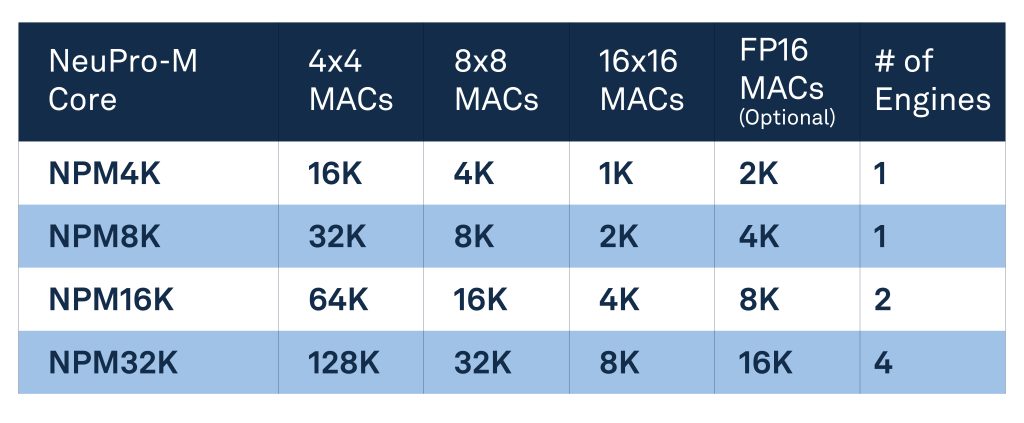
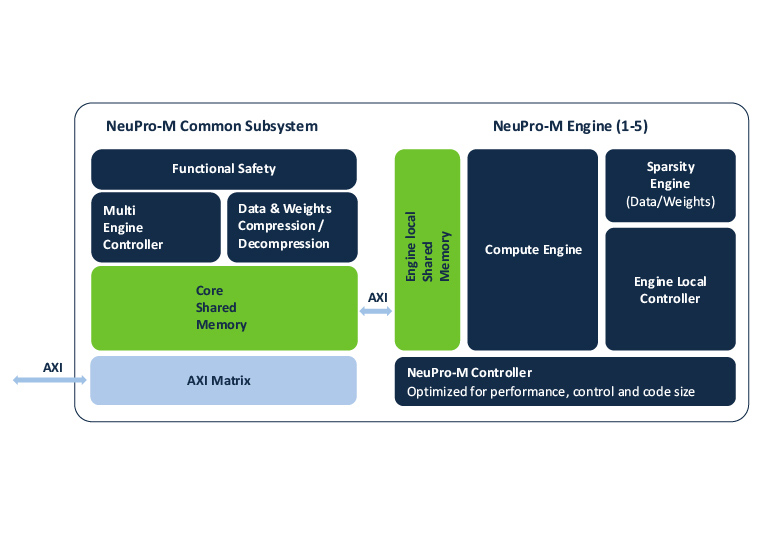
The heart of the NeuPro-M NPU architecture is the computational unit. Scalable from 4 to 20 TOPs, a single computational unit comprises a multiple-MAC parallel neural computing engine, activation and sparsity control units, an independent programable vector-processing unit, plus local shared L1 memory and a local unit controller. A core may contain up to eight of these computational units, along with a shared Common Subsystem comprising functional-safety, data-compression, shared L2 memory, and system interfaces.
These NPU cores may be grouped into multi-core clusters to reach performance levels in excess of 2000 TOPS.
The Ceva-NeuPro-M NPU family empowers edge AI and cloud inference system developers with the computing power and energy efficiency needed to implement complex AI workloads. It enables seamless deployment of multi-modal models and transformers in edge AI SoCs, delivering scalable performance for real-time, on-device processing with enhanced flexibility and efficiency.
The family can scale from smaller systems, for such applications as security cameras, robotics, or IoT devices, with performance starting at 4 TOPS, up to 2,000 TOPS multi-core systems capable of LLM and multi-modal generative AI, all using the same hardware units, core structure, and AI software stack.
Equally important, NeuPro-M provides direct hardware support for vital model optimizations, including variable precision for weights and hardware-supported addressing of sparse arrays. An independent vector processor on each computational unit supports novel computations that might be required in future AI algorithms. The family also provides hardware support for functional safety ISO 26262 ASIL-B.
With its enormous scalability and the Ceva-NeuPro Studio full AI software stack, the Ceva-NeuPro-M family is the fastest route to a shippable implementation for an edge-AI chip or SoC.


Reach out to learn how can Ceva help drive your next Smart Edge design
