

Now that we’re getting comfortable with 5G, network operators are already planning for 5G-Advanced, release 18 of the 3GPP standard. The capabilities enabled by this new release – extended reality, centimeter level positioning and microsecond level timing outdoors and indoors – will create an explosion in compute demand in RAN infrastructure. Consider fixed wireless access for consumers and businesses. Beamforming through massive MIMO RRUs must manage heavy yet variable traffic, while UEs must support carrier aggregation. Both need more channel capacity. Solutions must be greener, high performance and low latency, more efficient in managing variable loads, and more cost effective to support wide scale deployment. Infrastructure equipment builders want all the power, performance, and unit cost advantages of DSP-based ASIC hardware, plus all these added capabilities, in a more efficient package.

(Source: CEVA, ABI)
Virtual RANs and Vector Processing
Virtualized RAN (vRAN) components offer the promise of higher efficiency by being able to run multiple links simultaneously on one compute platform. These systems aim to deliver on decade-old goals of centralized RAN: economies of scale, more flexibility in suppliers and central management of many-link, high volume traffic through software. We know how to virtualize jobs on big general-purpose CPUs so the solution to this need might seem self-evident. Except that those platforms are expensive, power hungry, and inefficient in the signal processing at the heart of wireless technologies.
Embedded DSPs with their big vector processors are expressly designed for speed and low power in signal processing tasks such as beamforming, but historically have not supported dynamic workload sharing across multiple tasks. Adding more capacity required adding more cores, sometimes large clusters of them, or at best through a static form of sharing through a pre-determined core partitioning.
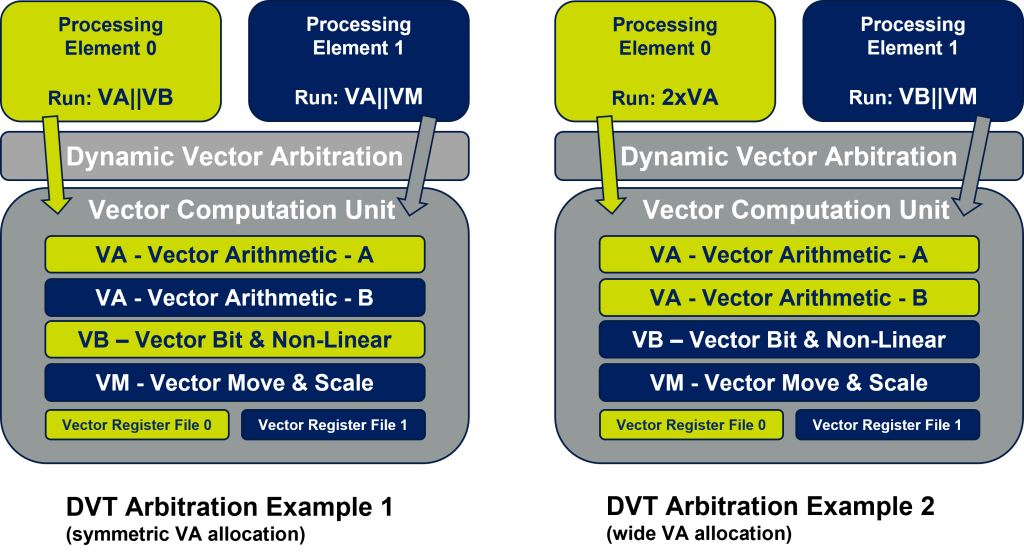
Dynamic Vector Threading
(Source: CEVA)
The bottleneck is vector processing since Vector Computation Units (VCUs) occupy the bulk of the area in a vector DSP. Using this resource as efficiently as possible is essential to maximize virtualized RAN capacity. The default approach of doubling up cores to handle two channels requires a separate VCU per channel. But at any one time, software in one channel might require vector arithmetic support where the other might be running scalar operations; one VCU would be idle in those cycles. Instead imagine a single VCU serving both channels, with two vector arithmetic and register files. An arbitrator decides dynamically how best to use these resources based on channel demands. If both channels need vector arithmetic in the same cycle, these are directed to the appropriate vector ALU and register files. If only one channel needs vector support, the calculation can be striped across both vector units, accelerating computation. This method for managing vector operations between two independent tasks looks very much like execution threading, maximizing use of a fixed compute resource to handle one or more than one simultaneous task.
This technique is dynamic vector threading (DVT), allocating vector operations per cycle to either one or two arithmetic units (in this instance). You can imagine this concept being extended to more threads, even further optimizing VCU utilization across variable channel loads since vector operations in independent threads are typically not synchronized.
Support for DVT requires several extensions to traditional vector processing. Operations must be serviced by a wide vector arithmetic unit, allowing for say 128 or more MAC operations per cycle. The VCU must also provide a vector register file for each thread, so that vector register context is stored independently for threads. A vector arbitration unit provides for scheduling vector operations, effectively through competition between the threads.
How does this capability support virtualized RAN? At absolute peak load, signal processing requirements on such a platform will continue be served as satisfactorily as they would be on a dual core DSP (each with a separate VCU). When one channel needs vector arithmetic and the other channel is quiet or occupied in scalar processing, the first channel completes vector cycles faster by using the full vector capacity. Delivering higher average throughput in a smaller footprint than two DSP cores.
Higher efficiency for beamforming and fixed wireless access
Another example of how DVT can support more efficiency in baseband processing can be understood in 5G-Advanced RRUs. These devices must support massive MIMO handling for beamforming. A massive MIMO RRU will be expected to support up to 128 active antenna units, including support for multi users and carriers. This implies massive compute requirements at the radio device, which becomes much more efficient with DVT. In UEs, terminals and CPEs supporting Fixed Wireless Access, carrier aggregation also benefits from DVT. DVT benefits at both ends of the cellular network, infrastructure and UEs.
Virtualized RANs need DSPs with dynamic vector threading
It might still be tempting to think of big general-purpose processors as the right answer to these virtualization needs but, in signal processing paths, that would be a backwards step. We cannot forget that there were good reasons the infrastructure equipment makers switched over to ASICs with embedded DSPs. Processors are expensive, power hungry and the wrong solution for signal processing. Competitive fixed wireless access solutions need to continue the benefits of ASIC-based DSPs, while also leveraging support for dynamic vector threading.
If you’d like to learn more, contact us. We have been working for many years with the biggest names in infrastructure hardware, many of them active customers of our wireless products. They have guided us towards this vision and have helped us validate our XC-20 family architecture and pre-release products.
Published in EDN.

Ceva