

In recent times, the need for real-time decision making, reduced data throughput, and privacy concerns, has moved a substantial portion of AI processing to the edge. This shift has given rise to a multitude of Edge AI applications, each introducing its unique set of requirements and challenges. And a $50B AI SoC market is forecast for 2025 [Source: Pitchbook Emerging Tech Research], with Edge AI chips expected to make up a significant portion of this market.
The Shift of AI processing to the edge and its Power Efficiency Imperative
The shift of AI processing to the edge marks a new era of real-time decision-making across a range of applications, from IoT sensors to autonomous systems. This shift helps reduce latency which is critical for instant responses, enhances data privacy through local processing, enables offline functionality, and ensures uninterrupted operation in remote or challenging environments. As these edge applications run under energy constrained conditions and battery powered devices, power efficiency takes center stage in this transformative landscape.
The Diverse Nature of Edge AI Workloads
One of the key complexities of ensuring power efficiency in Edge AI processing is the diverse nature of the workloads involved. Depending on the specific application, the workload can vary significantly and present its unique challenges. Overall, the whole spectrum of AI processing workloads can broadly be classified into TinyML, ML-DSP and Deep Learning workloads.
TinyML: Tasks such as sound classification, keyword spotting, and human presence detection necessitates low-latency, real-time processing near the sensors. These workloads are referred to as TinyML and involve running lightweight machine learning models on resource-constrained edge devices. TinyML models are tailored to specific hardware, allowing for smooth execution of AI tasks. Custom hardware processors and highly optimized software libraries are essential for meeting the stringent power requirements of TinyML.
Deep Learning: Conversely, deep learning applications represent a compute-intensive workload. These applications involve running complex computations and are often found in advanced computer vision, natural language processing, and other classic and generative AI-intensive tasks. Deep Learning, with its compute-intensive nature, often requires specialized hardware such as Neural Processing Units (NPUs), designed to handle the complexity of multi-layer neural networks. NPUs deliver the necessary compute power for advanced AI tasks at high power efficiency.
ML-DSP: In between the above two types of workloads are ML-DSP workloads that involve DSP processing, filtering and cleaning of signals before AI perception tasks can be performed. Radar is a common application that involves analysis of point-cloud images and falls into this category of workloads.
Workloads Determine the Architectures Adopted
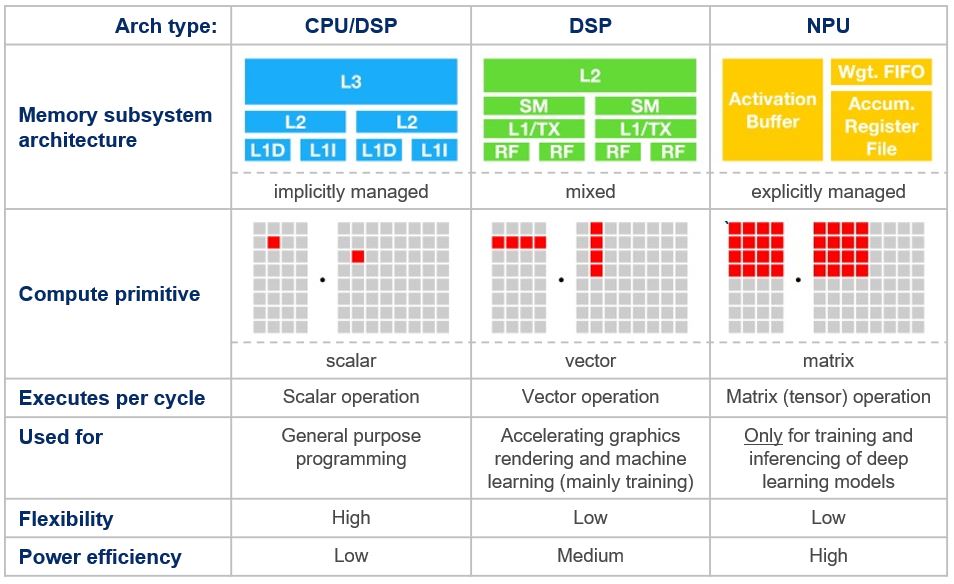
To address the multifaceted nature of Edge AI workloads and the power efficiency challenges they present, a variety of architectures and hardware engines have been developed. The choice of architecture and hardware for a particular workload is meant to deliver optimal compute performance while minimizing power consumption. As such, power efficiency is often specified using TOPS/Watt (Tera-Operations Per Second per Watt) as the metric. Matching the right architecture to handle the TinyML, ML-DSP and Deep Learning workloads is key to meeting the desired power efficiency metric.
Scalar Processing Architectures are best suited for TinyML workloads which typically involve user interface management and decision making based on temporal data and non-intensive compute requirements. Vector Processing Architectures are a good match where operations are performed on multiple data elements simultaneously and the workloads involve signal processing followed by AI perception. Tensor (Matrix) Processing Architectures are ideal for deep learning tasks involving complex matrix operations, image recognition, computer vision, and natural language processing. They effectively handle tasks involving large matrices and neural networks with the highest power efficiency. AI processors often use a combination of these architectures to handle a wide range of tasks efficiently. Refer to the diagram below.
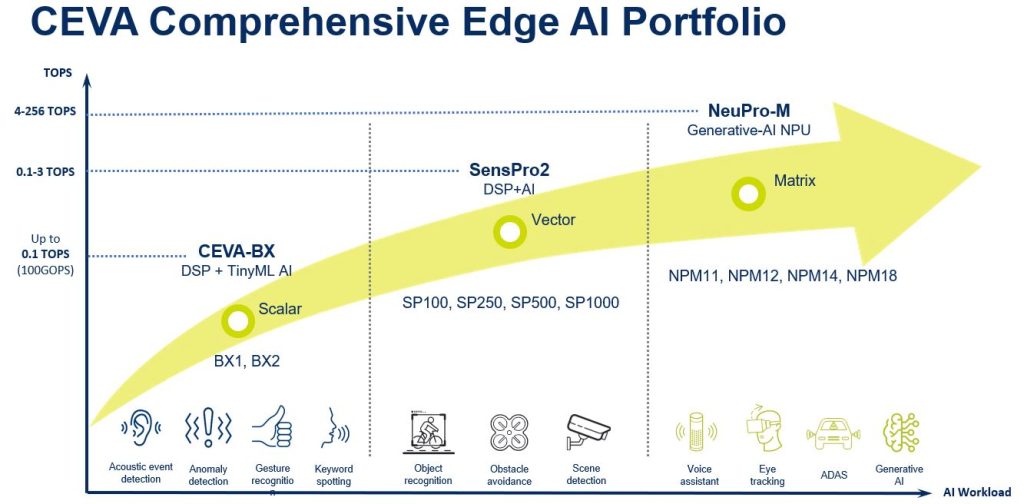
CEVA’s Products Address the Full Spectrum of AI Workloads
At CEVA, we offer a range of products designed to meet the requirements of TinyML, ML-DSP, and Deep Learning workloads. Our products, including CEVA-BX, SensPro2, and NeuPro-M, play a pivotal role in empowering edge devices with AI capabilities while ensuring power efficiency.
CEVA-BX processors are highly flexible and can be configured and optimized for specific applications, including audio and voice processing and AI-related workloads. Their architecture is designed to provide a balance between performance and power efficiency, making them suitable for a wide range of edge computing applications.
CEVA’s SensPro2 is a highly-configurable and self-contained vector DSP architecture that brings together scalar and vector processing for floating point and integer data types. It is designed for parallel high data bandwidth applications in computer vision and other sensors. It can efficiently handle AI workloads of up to 5 TOPS and incorporate up to 1,000 MACs. SensPro2 is a suitable choice for vision and radar systems that require high data bandwidth and AI processing capabilities.
CEVA’s NeuPro-M is a Neural Processing Unit (NPU) IP and is part of CEVA’s NeuPro family of deep learning AI processors. The NeuPro-M is designed to handle most of today’s classic and generative AI network models including transformers. It is specifically optimized for low-power, high-efficiency processing and includes a VPU (vector processing unit) and many other heterogeneous processing engines such as sparsity, compression, and activation logic. As AI network models rapidly evolve, NeuPro-M with its built-in VPU allows for future proofing one’s Edge AI application. Newer and more complex AI network layers not currently handled by the NeuPro-M can be efficiently managed by leveraging the VPU.
Summary
Between its Audio AI Processor, Sensor Hub DSP and NeuPro-M NPU IP and related software tools and development kits, CEVA addresses the needs of the full spectrum of Edge AI processing workloads.

Moshe Sheier