- Solutions
- Products
- Resources
- Company
 Investor Relations
Investor RelationsFinancial Information
- Careers


Ceva-SensPro is a family of DSP cores architected to combine vision, Radar, and AI processing in a single architecture. The silicon-proven cores provide scalable performance to cover a wide range of applications that combine vision processing, Radar/LiDAR processing, and AI inferencing to interpret their surroundings. These include automotive, robotics, surveillance, AR/VR, mobile devices, and smart homes.
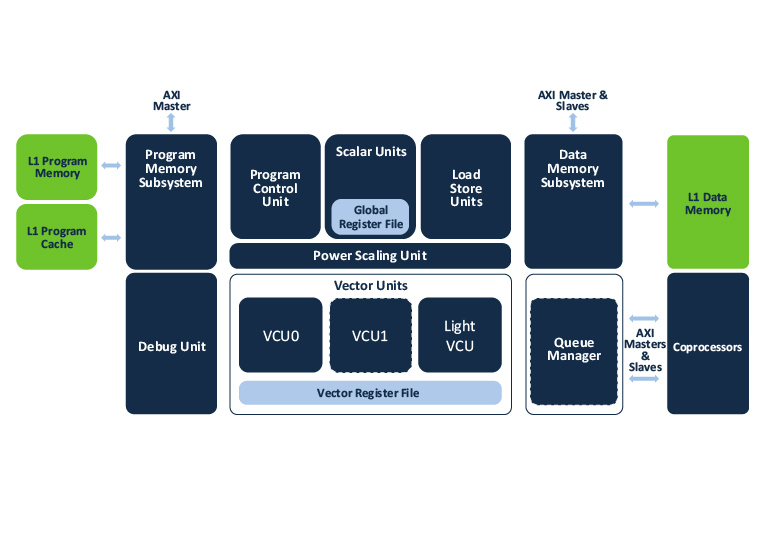
The Ceva-SensPro DSP family unites scalar processing units and vector processing units under an 8-way VLIW architecture. The family incorporates advanced control features such as a branch target buffer and a loop buffer to speed up execution and reduce power. There are six family members, each with a different array of MACs, targeted at different application areas and performance points. These range from the Ceva-SP100, providing 128 8-bit integer or 32 16-bit integer MACs at 0.2 TOPS performance for compact applications such as vision processing in wearables and mobile devices; to the Ceva-SP1000, with 1024 8-bit or 256 16-bit MACs reaching 2 TOPS for demanding applications such as automotive, robotics, and surveillance.
Two of the family members, the Ceva-SPF2 and Ceva-SPF4, employ 32 or 64 32-bit floating-point MACs, respectively, for applications in electric-vehicle power-train control and battery management. These two members are supported by libraries for Eigen Linear Algebra, MATLAB vector operations, and the TVM graph compiler. Highly configurable, the vector processing units in all family members can add domain-specific instructions for such areas as vision processing, Radar, or simultaneous localization and mapping (SLAM) for robotics.
Integer family members can also add optional floating-point capabilities. All family members have independent instruction and data memory subsystems and a Ceva-Connect queue manager for AXI-attached accelerators or coprocessors. The Ceva-SensPro2 family is programmable in C/C++ as well as in Halide and Open MP, and supported by an Eclipse-based development environment, extensive libraries spanning a wide range of applications, and the Ceva-NeuPro Studio AI development environment.
The Ceva-SensPro DSPs are architected to deliver environmental awareness through a blend of vision processing, sensor fusion, and deep-learning models in an embedded/edge computing environment. Covering the huge range of performance levels from 0.2 TOPS to 2 TOPS, offering both integer and floating-point implementations, and with a correspondingly wide range of area and power profiles, the family has a member ideal for any application—from lightweight wearables to automotive power-train control or robotics.
The architecture is optimized to perform multiple-sensor processing such as camera, Radar, LiDAR, or time-of-flight, followed by AI inference. Hardware support for multitasking allows efficient blending of these sensors processing and AI tasks on one platform, saving power and area by eliminating the need for separate sensor-processing DSP and AI accelerators, making the Ceva-SensPro an ideal embedded vision and AI processor.
Ever wondered how robots navigate or AR overlays stay perfectly aligned? The magic lies in SLAM, or Simultaneous Localization and Mapping. This video showcases a joint SLAM demo by Ceva and Van-Gogh Imaging, accelerated by Ceva’s powerful Ceva-SensPro2 DSP.
Tap the image below to watch the video




Get in touch
Reach out to learn how can Ceva help drive your next Smart Edge design
