

Siri and OK Google were initially a fun introduction to the promise of voice-based control, but we soon realized how carefully we must craft requests to get a useful response. The level of understanding we now see in ChatGPT would be much easier to use, but that capability has been limited to text interaction with cloud-based apps until recently. Now the compelling promise of ChatGPT and the ubiquity of cell phones is propelling a trend to make transformer networks for a ChatGPT mobile a reality, extending the power of large language models to everyone with a phone.
An obvious challenge is that the ChatGPT we know depends on trillions of parameters. Transformer networks of this size can only run in the cloud. Some suggest a hybrid model where a phone or other app does some of the work, connecting to the cloud for heavier duty inferencing. However, a casual phone-based user may not appreciate the long latencies and privacy risks inherent in a hybrid solution. A better approach would allow for running most or all of the transformer network load directly on the phone, turning to the cloud only for occasional anonymized search requests if needed.
Slimming down the network
How is it possible to fit a giant transformer network on a hand-held device? A major breakthrough came from Google DeepMind in retrieval transformers. Their RETRO transformer network runs to only a few percent the size of LLM transformers since it does not include factual data in model parameters. It only keeps the basic language conversation skills yet is still comparable to GPT3 in level of understanding. This reduction drops network size down to about 8 billion parameters.
At CEVA we prune this network further in pre-processing, retraining by zeroing parameters that have little impact on accuracy for prompts in the domain(s) of interest. This feature when exploited carefully can greatly accelerate transformer network analysis.
The second step in preparing a model for the edge – compression – is familiar but we at CEVA have taken it a lot further in support of retrieval transformers. We enable retraining to push this option hard, allowing for a wide range of mixed precision fixed point and low precision options, all the way down to 4-bit and even 2-bit in the future, taking full advantage of NeuPro-M support across this range.
Using these techniques we can compress an existing retrieval transformer, already significantly compressed over an LLM, by as much as 20:1. Adding this pruning and compression to the RETRO model reduction can convert a trillion-parameter model into a billion-parameter model, a huge reduction, making ChatGPT mobile a very real possibility.
The NeuPro-M AI core
Of course, it is not enough for the transformer network to simply fit. It also needs to run fast enough to meet user response time expectations. We accomplish through our NeuPro-M NPU IP multi-engine architecture, optimized specifically for LLM applications. An important first step in this flow is managed by our true sparsity engine. As a reminder, sparsity management increases throughput by skipping redundant operations where weight or data is zero. Pruning in pre-processing generates lot of zeroes in parameters though these are not distributed uniformly. For this unstructured sparsity, a dedicated sparsity engine in each NeuPro-M processor core can deliver up to 4X performance advantage over conventional sparsity methods, with corresponding power reduction.
The next optimization builds on the fact that transformer architectures can be broken into discrete orthogonal operations which are very parallelizable. Here you can leverage the NeuPro-M multi-core architecture, supporting up to 8 cores. Transformer query, key and value computations stream through engines in batches, running in parallel across multiple cores sharing a common L2 cache. Parallelization adds value not only in the attention step but also in the softmax step, the normalization function following attention computation. Softmax can be a significant performance bottleneck in conventional AI systems. In NeuPro-M attention and softmax can be parallelized, so that softmax adds negligibly to throughput time. The massive parallelization NeuPro-M enables in transformer computation is illustrated in the figure below.
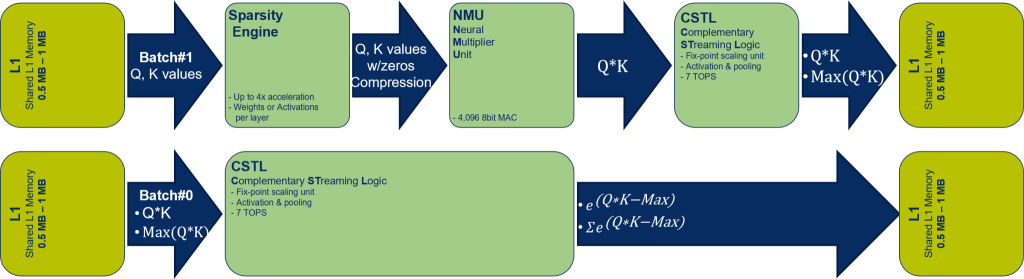
Extensive Parallelization in Transformer Computations
(Source: CEVA)
Further streamlining the high degree of parallelism in these flows together with data sharing between threads, the NeuPro-M architecture includes special support to maximize on-chip throughput with little or no stalling between threads.
Building a speech interface to a ChatGPT mobile
Once the hard part is done, adding speech recognition at the front end and text to speech at the back end can be handled through additional relatively simple transformer networks. Connect our ClearVox voice processing front-end software to a speech recognition transformer to input a prompt and to accept guidance on which of a set of refined prompts the main transformer should pursue. If necessary, retrieve a document relevant to the query from the internet. Finally, use a text-to-speech transformer to voice the response or document that was downloaded. Now that’s differentiation – an entirely speech based interface to a ChatGPT capability, all running on your phone.
Broader application
The NeuPro-M platform is not limited to GPT-class applications like ChatGPT mobile. It can equally well be applied to any generative method. For example you could implement a stable diffusion transformer to generate images, video or any other artificial or modified experience. The NeuPro-M solution is quite general in its ability to model transformer networks.
Contact us to learn more about the NeuPro-M NPU IP for AI Processor for transformer networks for implementing mobile chat capabilities on your device.

Roni Sadeh