

Packing applications into constrained on-chip memory is a familiar problem in embedded design, and is now equally important in compacting neural network AI models into a constrained storage. In some ways this problem is even more challenging than for conventional software because working memory in neural network-based systems is all “inner loop”, where demand to page out to DDR memory could kill performance. Equally bad, repetitive DDR accesses during inferencing will blow typical low power budgets for edge devices. A larger on-chip memory is one way to resolve the problem but that adds to product cost. The best option where possible is to pack the model as efficiently as possible into available memory.
When compiling a neural network AI model to run on an edge device there are well known quantization techniques to reduce size: converting floating point data and weight values to fixed point, then shrinking further to INT8 or smaller values. Imagine if you could go further. In this article I want to introduce a couple of graph optimization techniques which will allow you to fit a wider range of quantized models to say a 2MB L2 memory where these would not have fit after quantization alone.
Optimizing buffer allocation in the neural network AI graph
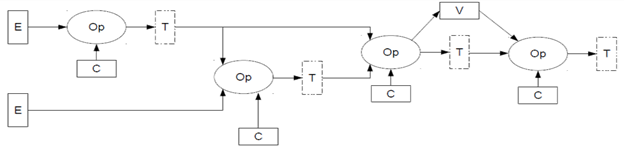
Figure 1. A simple AI graph. Op is an operator, E is an external input, C is a constant (weight), V is a variable and T is a tensor.
Neural network AI models are represented and managed as graphs in which operations are nodes interconnected through buffers. These buffers are fixed allocations in memory, and their size is determined during graph compile time to hold intermediate computation results or inputs to and outputs from the graph. The most basic kind of graph would be a pipeline, but more typically a simple graph would look like Figure 1.
Our goal is for the compiler to optimize total buffer memory demand. Consider one possible sequence of allocations in a simple neural network AI graph (the left graph in Figure 2). Understand first that different operations in the graph need different buffer sizes and an input buffer for a completed operation is no longer needed until the next wave of processing. Once a buffer A has been read (here allocated 800K bytes), it can be reused for a subsequent operation, as can buffer B, and so on. Where the graph branches, in the left graph A and B are first allocated to the right branch so a new buffer C must be allocated for the left branch.
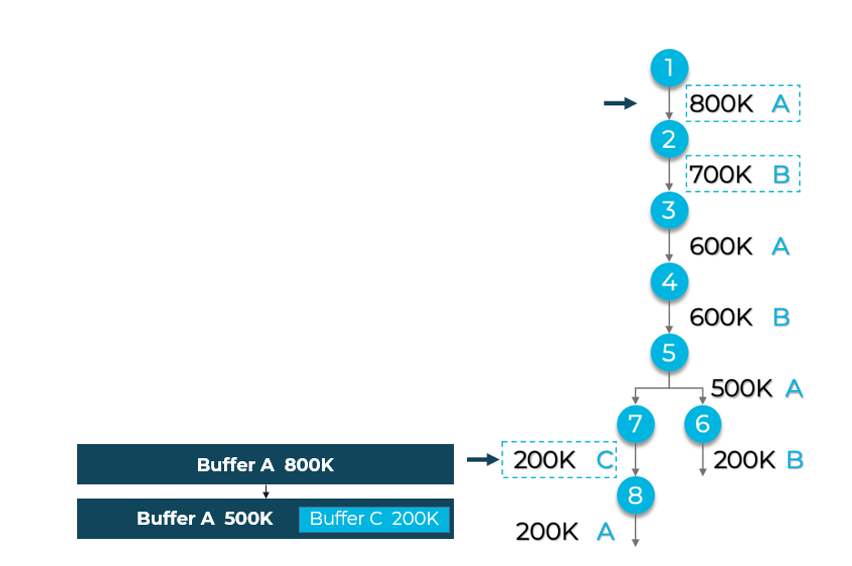
Figure 2. A simple graph illustrating buffer allocations. Allocation assignments on the left are improved on the right by switching B and C and oversizing B
It’s easy to see in this example that it would have been better to oversize B at the outset to 1000K, then later reuse the full capacity of B in the left branch, requiring only additional 10K buffer for C in the right branch, as shown in the graph on the right. The left/right memory demand difference is significant. The left graph requires 2.5MB (800K+700K+1000K), whereas the revised ordering on the right requires only 1.81MB (800K+1000K+10K).
Figuring out the optimal ordering in a general neural network AI graph is an example of the well-known 0-1 knapsack problem. We have run preliminary tests to study how well optimization can improve packing into a fixed size L2 memory. The results are quite impressive even at this preliminary stage. We tested several common networks for fit into an L2 memory sized at 2MB and then at 4MB. Before optimization, only 13% of the models fit into 2MB and only 38% fit into 4MB. After optimization, 66% of models fit into 2MB and 83% fit into 4MB. This optimization alone is well worth the effort to ensure more models can run entirely within on-chip memory.
Optimizing a neural network AI model through buffer merging
In convolutional neural network AI models, buffer sizes commonly shrink after the first few layers. This suggests that large buffers allocated at the outset could be used more effectively by sharing space with later smaller buffer requirements. Figure 3 illustrates this possibility.
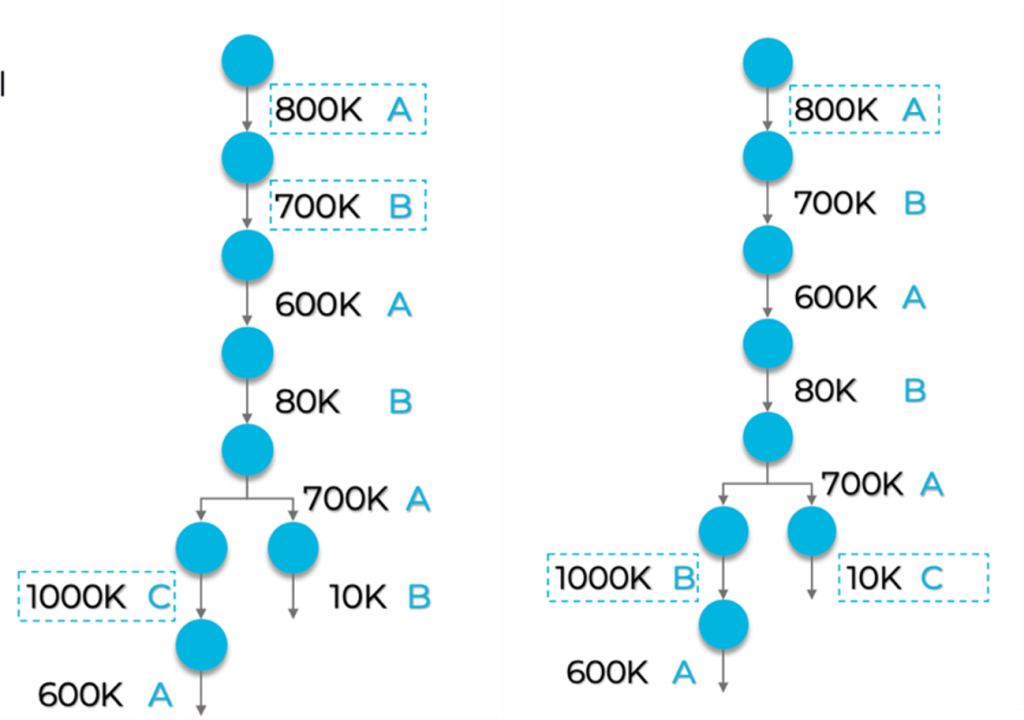
Figure 3. A different simple graph in which the initial allocation for buffer A can later be shared between the left and right branches: here the C buffer sits inside the initial A buffer.
We ran trial optimizations to see what difference this merging could make in total memory demand. Across a range of quite familiar networks, we saw reductions in total size anywhere from 15% to 35%. Again, these are very attractive improvements.
Takeaways
We have run a wide range of popular convolutional neural network AI models through these optimizations, from detection to classification to segmentation, and RNN models. Almost all have shown meaningful packing improvement, in many cases moving the model completely into a 4MB L2, or in some moving most of the model into L2, leaving only a part in DDR memory.
If your neural network AI model won’t fit inside your on-chip memory, all is not lost. There are buffer optimizations possible in the AI compiler stage which can significantly compress the total model size. At CEVA we would be happy to discuss these and other ideas to optimize memory usage for neural network AI models further.
Published on Embedded Computing Design.

Rami Drucker