

It is Tomer again with more about ENC! Throughout this journey, we’ve laid the foundation with an introduction and explored the pivotal factors to consider. We’ve also navigated the intricate world of noise classification, distinguishing between stationary and non-stationary types, while also delving into classical approaches for voice enhancement (scroll down to the end for part 1 and part 2 links). Now, in this 3rd part, we take a deep dive into the realm of AI audio: performing Environmental Noise Cancellation using Deep Learning methods. As we find ourselves at the forefront of a new era in acoustic advancements, join us in uncovering how these cutting-edge techniques are revolutionizing the battle against intrusive sounds, and shaping the future of auditory harmony.
The Power of Deep Learning in AI Audio
Deep learning methods have emerged as the state-of-the-art solution for environmental noise cancellation. Unlike traditional approaches that rely on meticulously hand-engineered algorithms to separate noise from desired audio, deep learning leverages the power of neural networks to automatically learn intricate patterns and relationships within vast amounts of data. This ability to adapt and learn from data is a significant departure from classical methods that often struggle to capture the complexity of real-world noise scenarios. Deep learning models excel at generalization, enabling them to handle a wider range of noise types and variations, a feat that traditional methods find challenging when using single channel, due to their fixed rule-based nature.
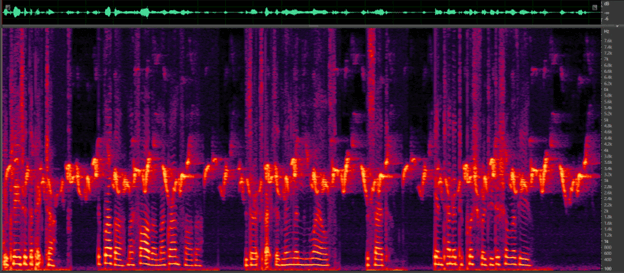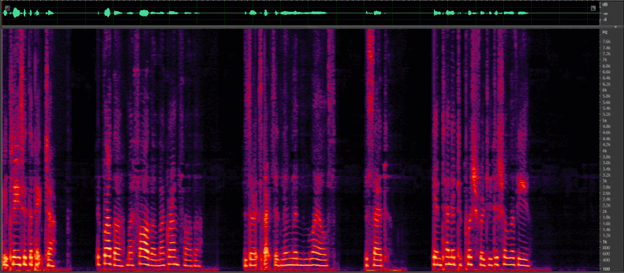
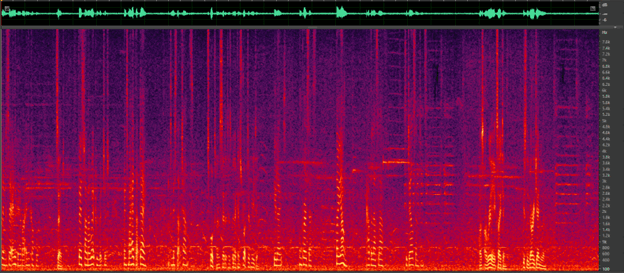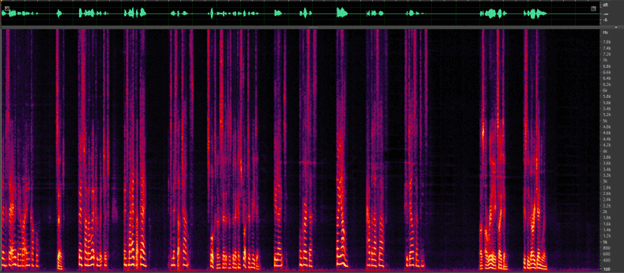
Figure 1: Noise reduction using CEVA’s Deep Learning solution. (a) traffic noise (b) birds chirping
The deep neural networks’ capacity to analyze and process complex temporal and spectral features makes them inherently suited to capturing the ever-changing nature of environmental noise. This adaptability translates into noise cancellation solutions that are not only more effective but also more versatile, capable of handling diverse and evolving noise environments without requiring constant manual adjustments.
The Journey of Data: Training the Voice Enhancement Model
The essence of deep learning lies in its remarkable capacity to extract patterns and insights from vast amounts of data. When training a Voice Enhancement model, we apply this fundamental concept by exposing the model to pairs of noisy and clean audio samples. These pairs act as the model’s teachers, guiding it to understand the complexities of noise. The true power of this process emerges from the volume of data and from its diversity and representation of real-world scenarios.
Selecting a diverse and comprehensive dataset is important, as it ensures that the model encounters a wide spectrum of noise variations, background environments, and signal types. By incorporating an assortment of noise sources, both stationary and non-stationary, the model learns to identify and mitigate noise across a gamut of situations. This is where the concept of data augmentation comes into play, introducing controlled distortions and variations into the dataset. These augmentations simulate the unpredictability of real-world scenarios, making the model resilient to different sources of noise and enhancing its generalization capability.
Crucially, the model’s transformative journey involves learning to differentiate between essential audio components and unwanted noise, much like how the human auditory system operates. As the model progresses through iterative training epochs, its internal parameters adjust in a dance of optimization, refining its understanding of the complex relationships within the data. This mimics the way our own brain adapts and refines its perception through learning.
The true testament to the efficacy of this process is revealed when the trained model is applied to real-time audio streams. With the knowledge it gained and the patterns it learned, the model can predict and remove noise very accurately, providing a quieter experience in noisy places. The model’s success depends on its skill not only in recognizing what noise is but also in understanding how it appears in different situations. Thus, the journey of training a noise cancellation model extends beyond algorithms and parameters; it becomes an exploration of data diversity, augmentation strategies, and the harmonious interplay of digital learning and human perception.
Aiming for the Target: Mapping-based or Masking-based Models
Masking-based methods and mapping-based methods are two distinct approaches for ENC using deep learning. Both aim to improve the quality of the desired audio signal by reducing the influence of unwanted noise, but they achieve this goal through different mechanisms.
Masking-based methods operate on the principle of spectral masking. They involve estimating a time-frequency mask that indicates the presence or absence of the target signal and noise at each time-frequency bin. These masks are then applied to the noisy spectrogram to attenuate the noise components and enhance the desired signal. Masking methods can be thought of as “soft” interventions, where the model guides the enhancement process by modifying the magnitudes of the spectrogram while leaving the phase largely unchanged.
Advantages of masking-based methods include their ability to effectively reduce noise without introducing significant distortion to the target signal. However, they may struggle in scenarios where the target and noise sources overlap significantly in the frequency domain, leading to incomplete noise reduction.
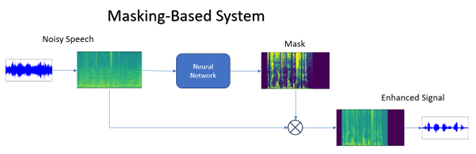
Figure 3: Masking-Based system scheme
Mapping-based methods take a different approach by directly mapping the noisy input spectrogram to a cleaner version. Instead of estimating masks, these methods learn a complex mapping function that transforms the input spectrogram to match the corresponding clean spectrogram. This approach is more akin to “hard” filtering, where the model makes explicit decisions about what parts of the spectrogram to enhance and what to suppress.
Mapping-based methods have the advantage of being able to handle complex transformations between the noisy and clean spectrograms. They can address issues like phase reconstruction and handling complex temporal relationships between different frequency components. However, they might introduce some artifacts if not trained carefully, as they impose a more direct transformation on the spectrogram.
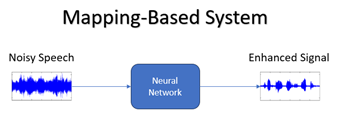
Figure 4: Mapping-Based system scheme
CEVA ClearVox AI-based ENC solution is a masking-based method designed to enhance the clarity of a signal while preserving the natural qualities of human speech, thus preventing distortions and undesirable artifacts.
Realizing the Potential: Applications and Challenges
The applications of deep learning in AI audio processing in general and ENC in particular, are far-reaching. From enhancing the audio quality of voice calls and virtual meetings to enabling quieter living spaces by neutralizing the hum of appliances, the potential benefits are undeniable. However, this promising technology also faces challenges. Building robust datasets that encompass diverse noise scenarios and maintaining a balance between noise reduction and signal distortion are among the hurdles researchers and engineers strive to overcome.
Our solution tackles these challenges head-on. By utilizing an optimal architecture, exposing it to vast and diverse datasets, performing a multitude of data augmentations, carefully selecting, and preparing the data, and setting the right training targets, we have successfully addressed these challenges. ClearVox AI-based solution represents a significant advancement in the field of ENC, offering a powerful and effective solution to enhance audio quality and reduce unwanted noise.
The Road Ahead: A Quieter Tomorrow
The evolution of sound processing techniques, particularly in the realm of ENC, reflects our unwavering commitment to overcoming the challenges posed by our ever-changing auditory landscapes. From the traditional methods of filtering and adaptive algorithms to the cutting-edge advancements in AI audio driven by deep learning, we have journeyed through a sonic revolution. Here at CEVA we work towards a seamless integration of ENC into our audio processing solutions, overcoming the challenges mentioned and redefining how we experience the world of sound. As we find ourselves at the threshold of new opportunities, it’s evident that our pursuit of exceptional audio quality and effective communication knows no bounds. With each innovation, we inch closer to a world where noise is no longer an obstacle, and where the symphony of human connection can thrive within any environment. So, let us continue to listen, learn, and create, for the future of sound is clearer and more vibrant than ever before.
Part 1: Enhancing Audio Quality with Environmental Noise Cancellation in Sound Processing
Part 2: Environmental Noise Cancellation (ENC): Noise types and classic methods for Speech Enhancement

Tomer Badug